An in-depth look at dealing with R-trees in Unity, complete with explanations, practical examples, optimization recommendations, and result analysis.

Hi all! My name is Almaz Kinziabulatov, and I’m a Unity programmer at MY.GAMES. In this article, we’ll discuss optimizing R-tree data insertion within Unity projects. There won’t be any code, but I’ll be comparing the results of the stepwise optimization process of the previously mentioned algorithm.
A bit of background information: some time ago, I decided to create a simple tank game with fully-fledged online multiplayer. My reference point was a well-known MS-DOS game from the 90s Dyna Blaster, better known as Bomberman.
Dyna Blaster: The starting menu and the first game location
I chose Bomberman due to its simple (yet addictive) gameplay. As a bonus, the original game has a local multiplayer mode for five players, and the idea of integrating online multiplayer into my game seemed quite natural.
And, well, there was one more important personal reason — this was the very first game that opened up the world of PC gaming to me.
Due to the project specifics, the gameplay needed to be deterministic, so I couldn’t use the physics engine that’s built into Unity. Consequently, I had to use a simplified version of the physics engine, namely collision detection + collision resolver.
The first solution that came to mind was the Spatial Hash data structure, in the form of a two-dimensional table, the dimensions of which are equal to the number of cells in the width and height of the playing field. Each cell contains a collection of entities/objects that are situated within it at the moment of world simulation. However, I wanted to work out a general solution for objects of random sizes and try to create a more complex data structure. That’s why I chose the R-tree.
An R-tree is an accelerating tree-like data structure for storage and access in some multidimensional space. The most simple example of such a structure is interactive maps.
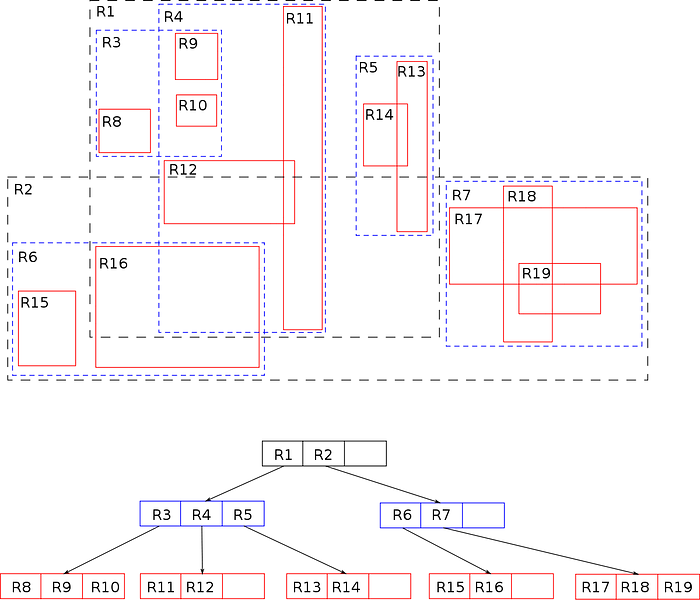
An R-tree in a 2D environment
Pictured above is a 2-unit tall R-tree filled with objects in a 2D environment. Each object position in that space is dependent on the object’s limiting size, AABB. The tree root nodes are marked in black, the inner child nodes marked in blue, and the leaf nodes marked in red; the leaf nodes are the ones that contain the objects themselves. Performing searches in such a structure is evaluated as O(logMn) and O(n), in the best and worst cases — here, M is a property of the tree and denotes the maximum number of child nodes for any node.
In addition to the maximum number of child nodes, R-trees have a limit on the minimum number of child nodes for each parent node, which is denoted as m. The root nodes contain at least two child nodes or have no such restriction at all. In games, R-trees are used, for example, to organize access to limiting volumes of game entities such as heroes, mobs, items, and so on.
The main goal of most R-tree implementations that differ from the original implementation of Guttmann (the author of the R-tree) is to reduce, or eliminate, the intersection between tree nodes. This in turn, increases the tree building time and/or increases the memory requirements. Since the game area objects make up grid-ordered blocks, Guttman’s implementation is appropriate to represent object locations relative to each other in the game world.
Guttman’s algorithm of inserting data into the R-tree is described in various sources, but within this article, a surface-level understanding of the algorithm will be enough:
- In the process of the next element’s fractal insertion, the internal nodes are mutually evaluated over the entire depth of the tree and then the final leaf node is determined where the insertion should occur.
- The node evaluation and selection are determined by logic specific to each R-tree implementation: a node is selected whose bounding box size will increase the least compared to neighboring nodes.
- When inserting data into a completely filled node (EntriesCount === M), the node splits and the tree height increases.
Let’s take a look at the result of the first version of the algorithm implementation:
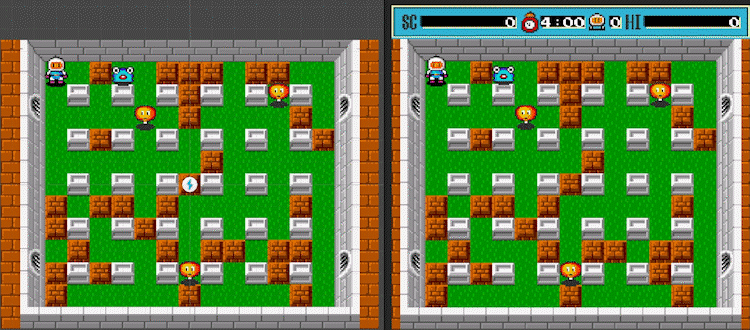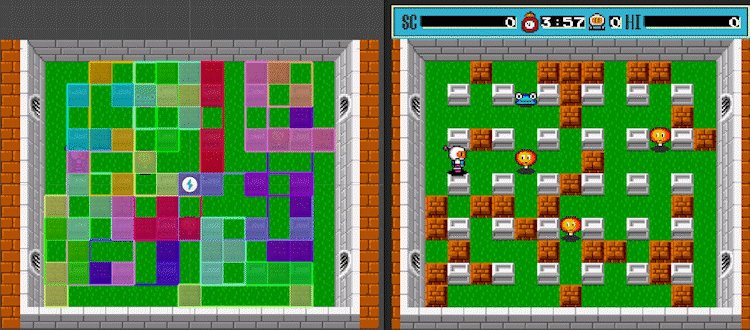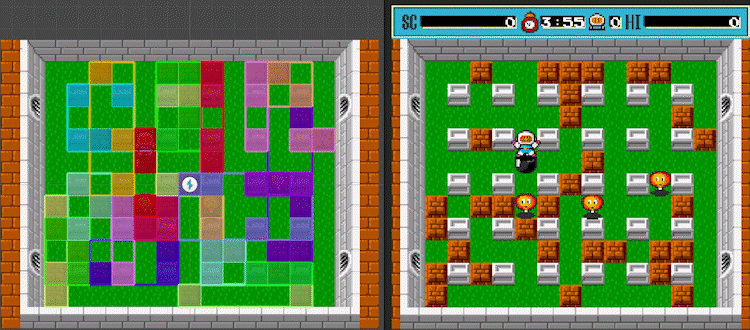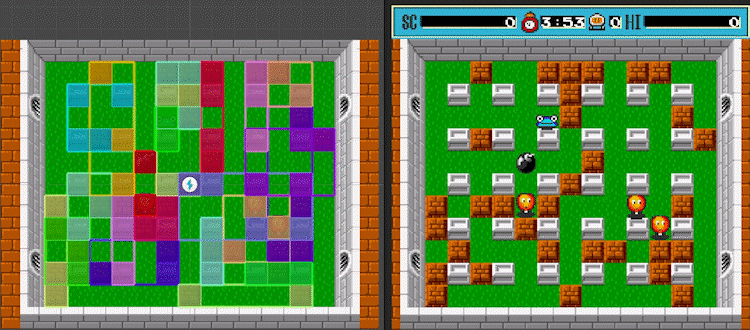
Leaf nodes of the R-tree, built on the basis of AABB colliders of game entities
This result was quite satisfactory, that is, until I used the profiler for the insertion algorithm within the frame:
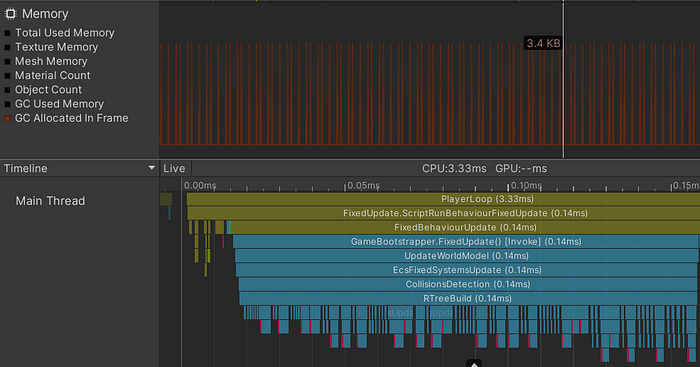
The result of profiling a tree insert — 150 game entities
Although the insertion time into the tree is relatively short, there are huge jumps in the allocation and release of memory in the heap. This is, obviously, not good, not only because of the potential memory fragmentation, but also because of the frequent activation of the garbage collector, which takes up part of the frame time, leading to FPS drops. The situation becomes even more aggravated when the number of processed game entities is significantly increased.
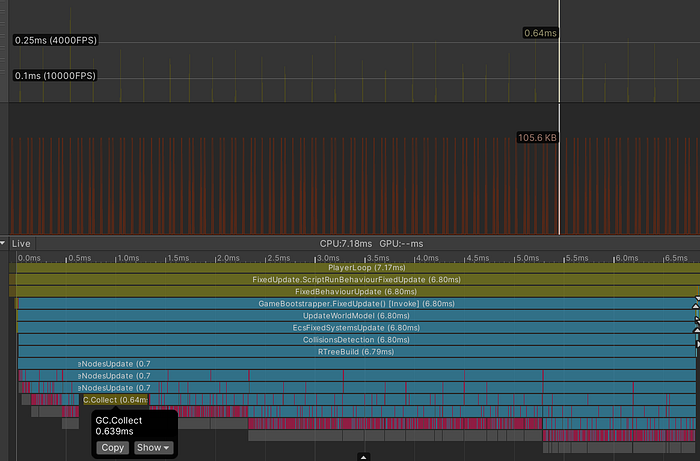
The result of profiling a tree insert — 1500 game entities
Unity has to call the GC.Collect method noticeably more often — the frequency of memory allocations increases significantly as a result of the greater number of game entities. In the lower part of the screenshot, you can see how the GC.Collect call interrupts the process of building the tree, and in the upper part of the screenshot, the so-called GC spikes are clearly marked as spikes displaying the load on the garbage collector.
The problem is obvious — we need to get rid of memory allocations in the heap. But before doing that, it would be interesting to check how the picture will change when we use different implementations of the garbage collector on different scripting backends.
Unity uses the Boehm–Demers–Weiser garbage collector implementation by default. This implementation allows the game to continue running, because it doesn’t allocate resources to one system — the garbage collector — but instead distributes the execution of garbage collection algorithms over time. Unity allows you to turn off the incremental garbage collection system and use the stop-the-world implementation of the collector instead. I took advantage of this, and here’s a comparison of the final results:
On the left is the Mono backend, on the right is IL2CPP; the incremental garbage collection variant is highlighted in blue, the stop-the-world in orange. Further, in profiling, IL2CPP will be used as a scripting backend
As a result, I found several reasons for memory allocation:
- Memory allocation in containers of internal and leaf nodes during tree growth
- Boxing when using non-generic enumerators
- Boxing when using the Object.Equals() comparison methods when comparing structure instances
- Creating lambda functions with capture and transferring them as a parameter to the method
- Activation of the compiler’s “defensive copy” behavior pattern when using non-readonly structures
Having gotten rid of the above problems, I obtained the following result:
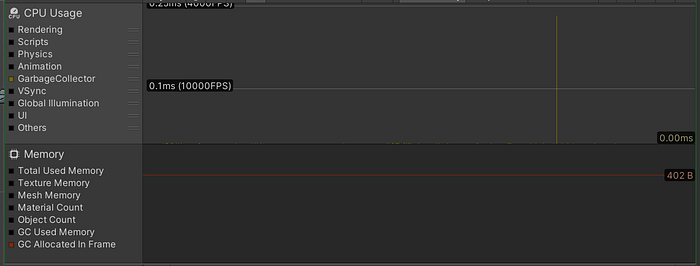
The result of inserting 9601 objects: in the upper half, you can see the only GC.Collect call within 1000 frames indicated in yellow, and no memory allocations in the lower half
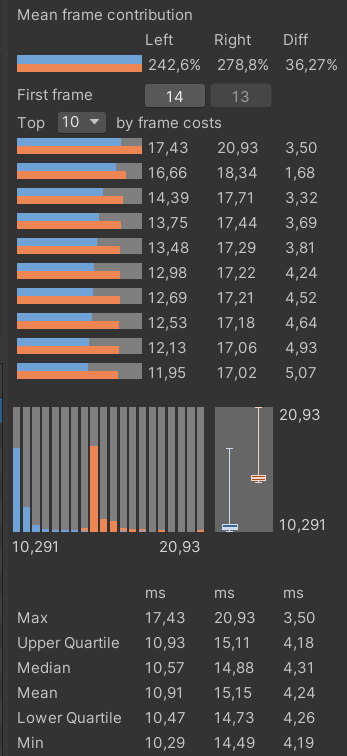
Insertion time statistics for 9601 objects: orange indicates before, and blue, after
The GC.Collect call now occurs much less frequently: about once every 1000 frames, and the memory allocation schedule has evened out. Our win was a little more than 4 milliseconds per frame: 10.57 versus 14.88 ms. In general, not bad — but I still wanted a greater acceleration. Therefore, I decided to shift the algorithm calculation to several threads.
Since version 2018.1, Unity has provided an API for working with Job system threads. Thanks to this system, it’s possible to distribute the load from one thread to several simultaneously. The more cores a device’s processor has, and the more threads are involved, the greater the benefit of using threads.
To transfer the algorithm to a multi-threaded version, it’s necessary to transfer the storage of all the input and output data to unmanaged containers — one of which is NativeArray. In fact, this is a piece of memory allocated on the heap, the lifetime of which is not controlled by the built-in language tools. It also allows you to store non-blittable and unmanaged types, and avoid marshaling overhead when passing data between managed and unmanaged code.
In addition to changing data storage, it’s necessary to transfer the logic of the algorithm to Jobs. Jobs are structures that inherit one of the IJob or IJobParallelFor interfaces. These structures contain data and methods for reading and modifying said data. Jobs are executed by workers — one instance of a worker per thread. The entry point of a job is the Execute() method. Each job type has its own signature for this method. To distribute the algorithm execution to several threads, the structure, which is a set of data and methods that process data, should inherit the IJobParallelFor interface.
The key point to consider during the transition to multi-threaded data processing is strict data separation and minimization of dependencies between workers. To do this, it’s necessary to change the existing algorithm in such a way that the tree is divided into several subtrees, one per worker, and the input data container from the game objects is also divided into equal parts between the workers. The same thing happens to the container with the algorithm results. Now, the worker only contains the data which it must collect into a subtree, and the subtree itself is merged with others into one common tree for an external user, for example, for the collision resolver.

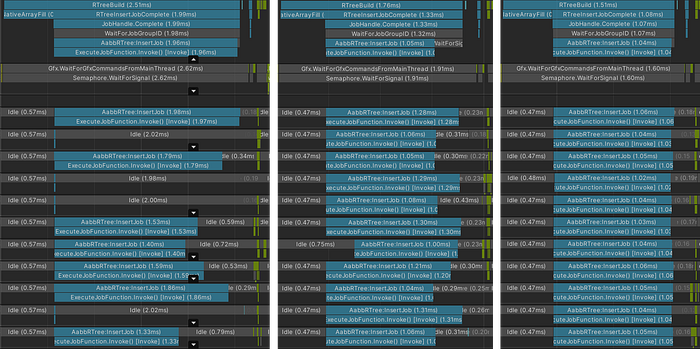
On the left screenshot, there’s an “average” frame when the work is distributed among several threads, on the right is a comparison of statistics on frames of single-threaded and multi-threaded implementations
On my device, with a 12-thread processor, Unity can allocate all 12 threads for jobs. On the profiler timeline, you can see that all the work was distributed exactly among 12 workers. Apart from the workers operation, the timeline reflects the work of another method: NativeArrayFill. As the name might suggest, this piece of code moves data from a managed container into an unmanaged NativeArray. In order to not waste time on this, you can transfer the source data storage to unmanaged containers, which, in the case of my project, meant a deep rework of the ECS framework.
Another option is to start a system where the necessary data will be filled in at each tick of the world simulation. This option seems more like a half-measure than a real solution, and the first option is too time consuming to consider it an ad-hoc optimization. For these reasons, data shifting will remain inside the tree building algorithm method. But it’s worth noting that if you initially store all data about the game world entities in native containers, then the total tree building time will be determined only by the time of a worker group operation, the median value of which, judging by the “average” frame, is 1.32 ms.
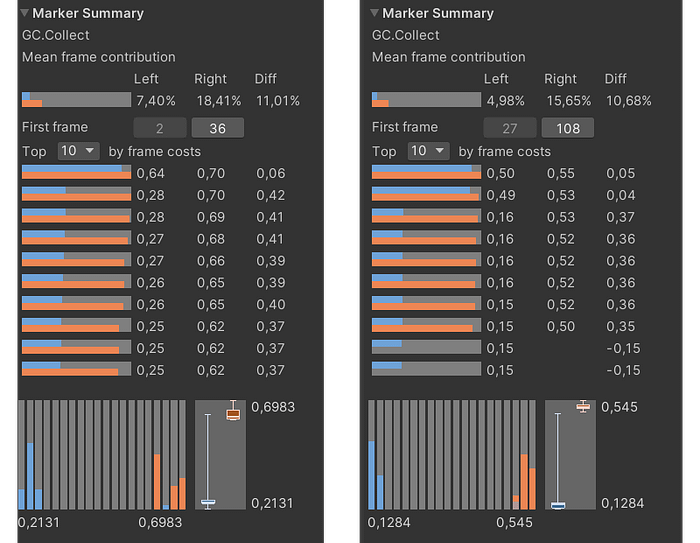
In general, the acceleration of the tree building process is significant, but if we analyze the statistics for a group of workers separately from the single-threaded version, excluding the influence of data shifting into the native NativeArrayFill container, it turns out that there is some dispersion in statistics:

A box plot for insertion algorithm implementation on 12 workers
According to the box plot, the top and bottom quartiles don’t diverge from each so much — which is good. But the maximum and minimum values are suspiciously far apart. This may indicate that in several frames, some workers finish earlier or later than others, and some may not be activated at all, as a result, the overall algorithm running time increases since the final value is determined by the execution time of the slowest worker.
Unity task scheduler examples (from left to right): bad, acceptable, ideal
The left screenshot illustrates a case where Unity, for some reason, decided to utilize the smaller number of threads that are available to it on the current device. The one in the middle shows the “acceptable” scenario for the scheduler work — most of the workers started at the same time, but not all of them completed working at the same time. The consequence is that the total running time of the workers is greater than the running time of the same workers in the “ideal” case on the right screenshot.
This happens because the Unity scheduler neither guarantees an even distribution of the load among the workers, nor the simultaneous launch of jobs amongst them. To reduce the impact of this scheduler feature, it’s necessary to divide the input data into smaller pieces: batches. This is done in order for the workers to “steal work” from other workers if the latter can’t finish their work in time — the work stealing approach.
To schedule a batch processing job, the IJobParallelFor interface isn’t sufficient. To do this, we need to use another job type: IJobParallelForBatch. Little is said about this interface in the documentation, but the only way it differs from IJobParallelFor is that the load is transferred to such a job in the form of a certain range of processed data (a batch).
Thus, it’s possible to divide the input data into small pieces and expect that each individual worker will expand its own tree at each call to the Execute() method, selecting a fixed-size batch from the general data collection. Which, theoretically, should exclude situations like on the screenshot above with a “bad” version of the scheduler.
I decided to go a little further and implement my own job type. This made it possible to move the primary initialization of each individual worker from the ICustomJob.Execute() job method inside the custom JobProducer. The GetWorkStealingRange method inside the JobProducer selects a range of input data to be passed to the jobs themselves for processing. Below is a comparison of a group of workers operation without taking into account the time spent transferring data to a native container.
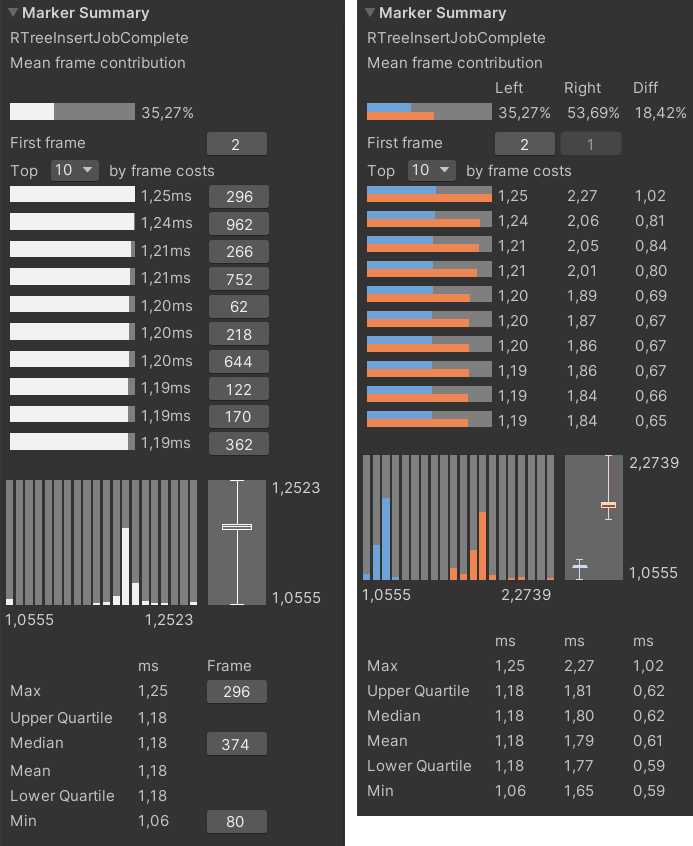
On the left is the statistics of the workers batch load. On the right is a comparison of the execution time of a group of workers with and without batch load planning
The values of the upper and lower quartiles don’t differ from the median value, which has a positive effect on the overall execution time of the algorithm, and the minimum and maximum values are now much closer to each other. Even in the “worst” frame, the workers are perfectly lined up along the timeline:

The “worst” frame
As a result, the transfer of the algorithm to the workers gave a significant performance boost compared to the original implementation of the tree insertion algorithm:

Comparison of the original version with the multi-threaded version.
It’s worth mentioning that the work stealing approach means that now the subtrees of each individual worker will intersect much more often for obvious reasons. This can adversely affect the performance of tree search algorithms. But this problem can potentially be solved if the batches themselves are built based on their spatial position, for example, as in the lowx/lowy packed R-tree or Hilbert R-tree implementations.
The next stage of optimization is optimization using the Burst Compiler. This allows us to optimize existing code almost “for free”. All that’s required of the developer is to adjust the code to the requirements of the compiler itself. Having slightly changed the storage and reading of data, as well as the algorithm code in the workers, the following result was obtained:
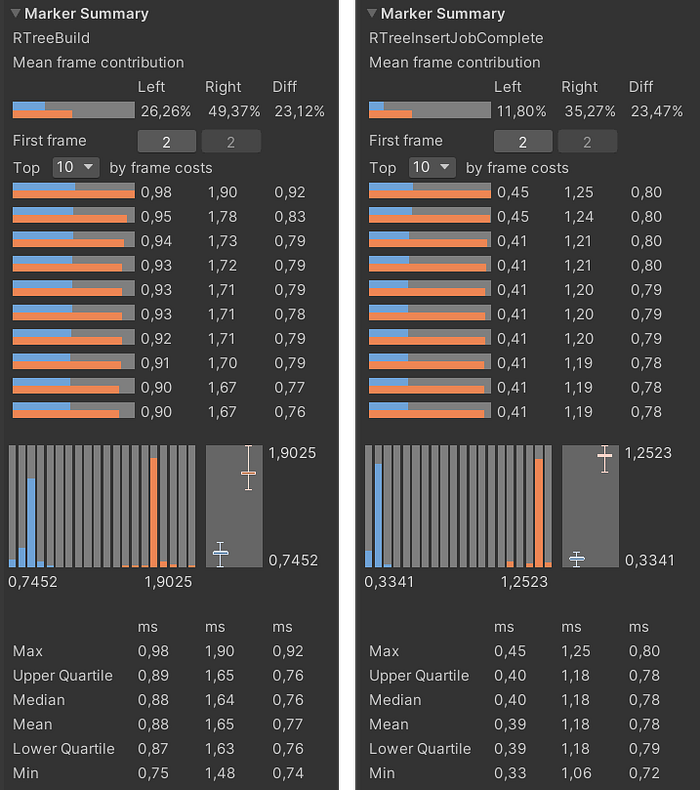
Blue color indicates Burst optimization by the compiler: the left screenshot takes into account the time spent transferring data to the native container, the right does not
The obtained optimization result is more than satisfactory — the current 0.40/0.88 ms vs the original 14.87 ms. In general, this is where I can wrap up my story. But there are several other ways to speed up the algorithm.
For example, as mentioned above, instead of floating-point numbers, the project uses fixed-point numbers. One of the disadvantages of this type is a bigger number of processor instructions in arithmetic operations and a bigger memory footprint compared to float32. If we transfer the calculations inside the algorithm to single-precision floating-point numbers, then we can speed up the algorithm by another two or three times. In addition, if the precision of floating-point calculations doesn’t matter, you can specify low precision through the appropriate FloatPrecision flag on the BurstCompile attribute and save a few more microseconds on calculations.
Loops are good candidates for optimization via vectorization. The compiler handles this quite well on its own, but if there are branches inside the loop body, vectorization may not be possible. If such cycles are rewritten taking into account potential vectorization, there exists a chance to get additional acceleration in the algorithm. In order not to dive deep into the optimized assembler code in search of problem areas, you can use the Loop.ExpectVectorized() intrinsic for validation at the code compilation stage in loops and, if it’s confirmed that there is no vectorization, try to rewrite the problematic code section if possible.
In some cases, the use of the NoAlias attribute can help. This attribute tells the compiler that certain variables will not intersect in memory, which allows the compiler not to access memory for the value of the same variable during calculations.
When optimizing via multi-threading, it is worth considering the location of data in memory, the size of the batch, and the number of workers/threads used — in some cases, fine-tuning in this direction can reduce the cache miss rate.
And the last optimization option is refactoring the entire algorithm, taking into account the above. Perhaps, even up to the transition to another implementation of the R-tree.
.png)

